| sf100 | sf500 | sf1000 |
|---|---|---|
| h16 | h07 | h05 |
| h17 | h12 | h07 |
| h18 | h16 | h11 |
| h17 | h12 | |
| h18 | h16 | |
| h20 | h17 | |
| h21 | h18 | |
| h20 | ||
| h21 |
tl;dr
DataFusion, despite lacking out-of-core support for some TPC-H queries, offers an extensible approach to constructing OLAP databases using Arrow-based building blocks and exhibits strong performance in areas where the community has invested.
Introduction
In recent years, there has been a growing trend1 towards unbundled OLAP (Online Analytical Processing) architectures. In these architectures, the various components of a database, such as APIs, protocols, query engines, and storage systems, are decoupled. This allows for better utilization of cloud resources, the ability to select the necessary database parts based on specific use cases, and easier integration of SQL pipelines into code and systems. In this article, we look at DataFusion as an example of unbundling.
The Big Unbundling
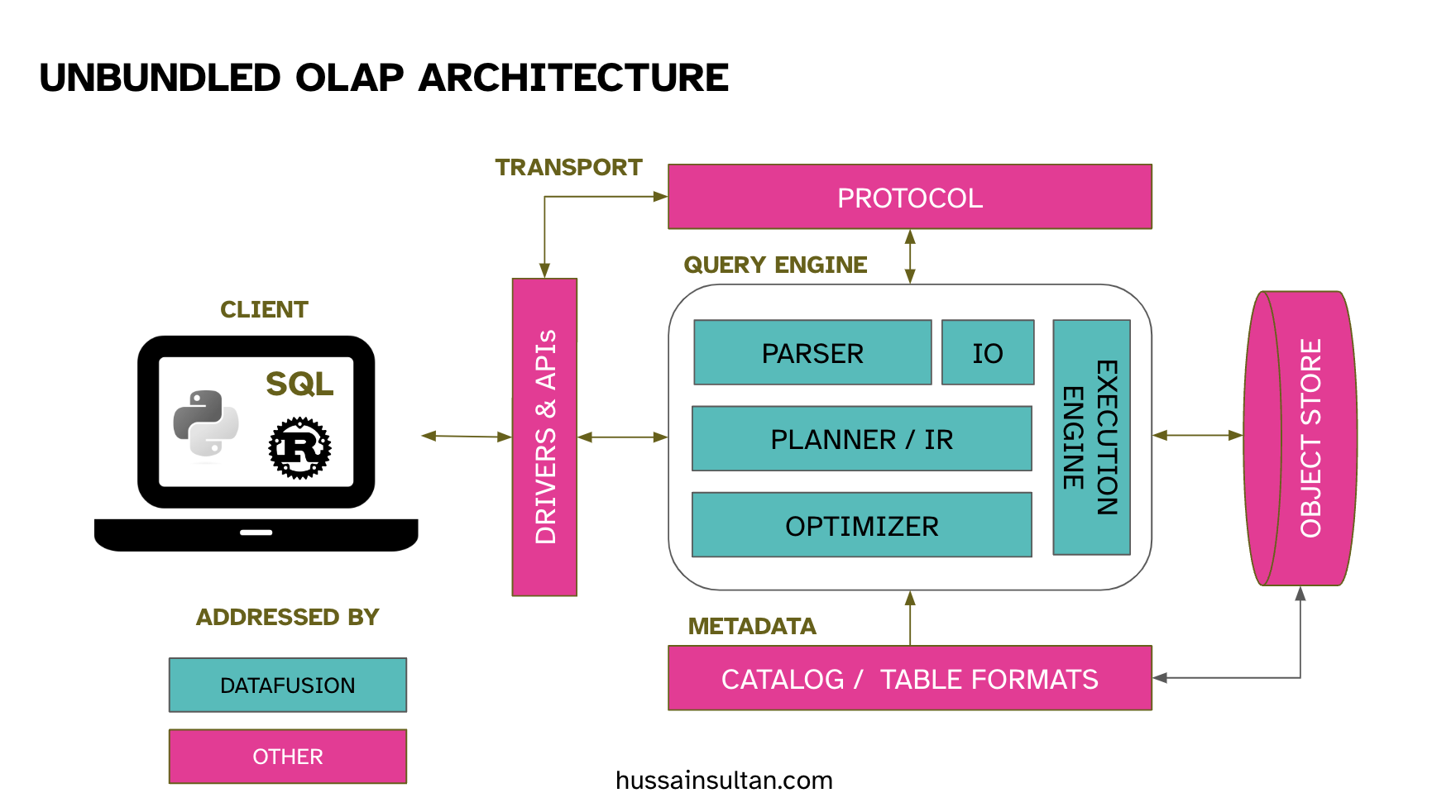
In an unbundled OLAP (Online Analytical Processing) architecture, the various components such as APIs, protocols, query engines, and storage systems are decoupled, allowing for better utilization of cloud resources and the ability to select the necessary database parts based on specific use-cases. When a SQL query is submitted, it is first transformed into a relational algebra representation and then converted into an executable plan through optimization. This executable plan can then be executed by a query engine.
This unbundling process renders the transport and protocol layers optional, enabling direct queries of Parquet files in Object Stores from thin or fat clients. As a result, there is no need for network transport and protocol overhead when managing data transfers. This allows analysts, data scientists, and developers to easily integrate SQL pipelines into their code and systems without worrying about setting up servers or networking infrastructure.
Examples of unbundled OLAP architectures include:
DataFusion: A prominent example of an unbundled OLAP architecture that facilitates the development of high-performance, versatile data systems. It relies on sqlparser-rs, a Rust library that offers SQL parsing capabilities with dialect extensions. DataFusion is able to glue together all the building blocks by using Arrow in-memory format for zero-copy interop. The parsed syntax tree is then transformed into DataFusion’s Logical Plan, which can be optimized using a pluggable system. The community actively contributes new operators and discusses experimental optimizers. Commercially, DataFusion has been used to build various data systems for time-series, streaming, and OLAP use-cases2.
DuckDB is another query engine that supports SQL, and perhaps the most celebrated example of unbundled OLAP. However, DuckDB’s SQL parser, optimizer, vectorized compute primitives, and IO components are not as easily accessible as separate components when compared to other query engines like DataFusion. I looked at the DuckDB benchmarks on the same hardware in my previous article. Like DataFusion, DuckDB also supports Arrow memory format for interop with other tools.
Benefits:
- Better utilization of cloud resources
- Ability to select the necessary database parts based on specific use cases
- Easier integration of SQL pipelines into code and systems
- Reduced need for networking infrastructure
DataFusion Example: Distributed SQL Processing with DataFusion and Ray
RaySQL uses DataFusion’s planner and optimizer, modifies it, and adds distributed operators to the plan, which can then be scheduled by a generic task scheduler like Ray. This is just an example of how unbundling can drive innovation in different parts, Ray in case of distributed task scheduling, and DataFusion for query execution – validating sum of parts to be greater than the parts. This example extends the execution engine components of the figure above with a distributed scheduler and teaches datafusion about new operators.
DataFusion Example: delta-rs
delta-rs is a Rust based connector for delta. It implements a Table Provider for delta tables as a custom data source as well as expression evaluation, including filtering and predicate pushdowns. Here is the official example.
Benchmarks
This benchmark modified the official TPC-H specifications by storing the data in parquet format as a single file. I test3 all 22 queries in the TPC-H dataset using the modified queries from the sql-benchmarks repo as DataFusion’s SQL does not support some subquery functionality. The goal of this benchmark is to understand how the out-of-core performane scales as the data size increases and also tracks the execution time per various TPC-H queries.
In general, DataFusion shows poor out-of-core performance necessary to handle larger than memory data and lacks support for certain operators in the standard TPC-H queries.
Based on the results:
- DataFusion shows state-of-the-art performance in places where the community has invested, e.g., multi-column sorts. This indicates that further optimizations are not only possible but also likely due to the hive mind of open-source.
- As compared to a tightly integrated system like DuckDB, DataFusion is fast approaching it in terms of performance and features.
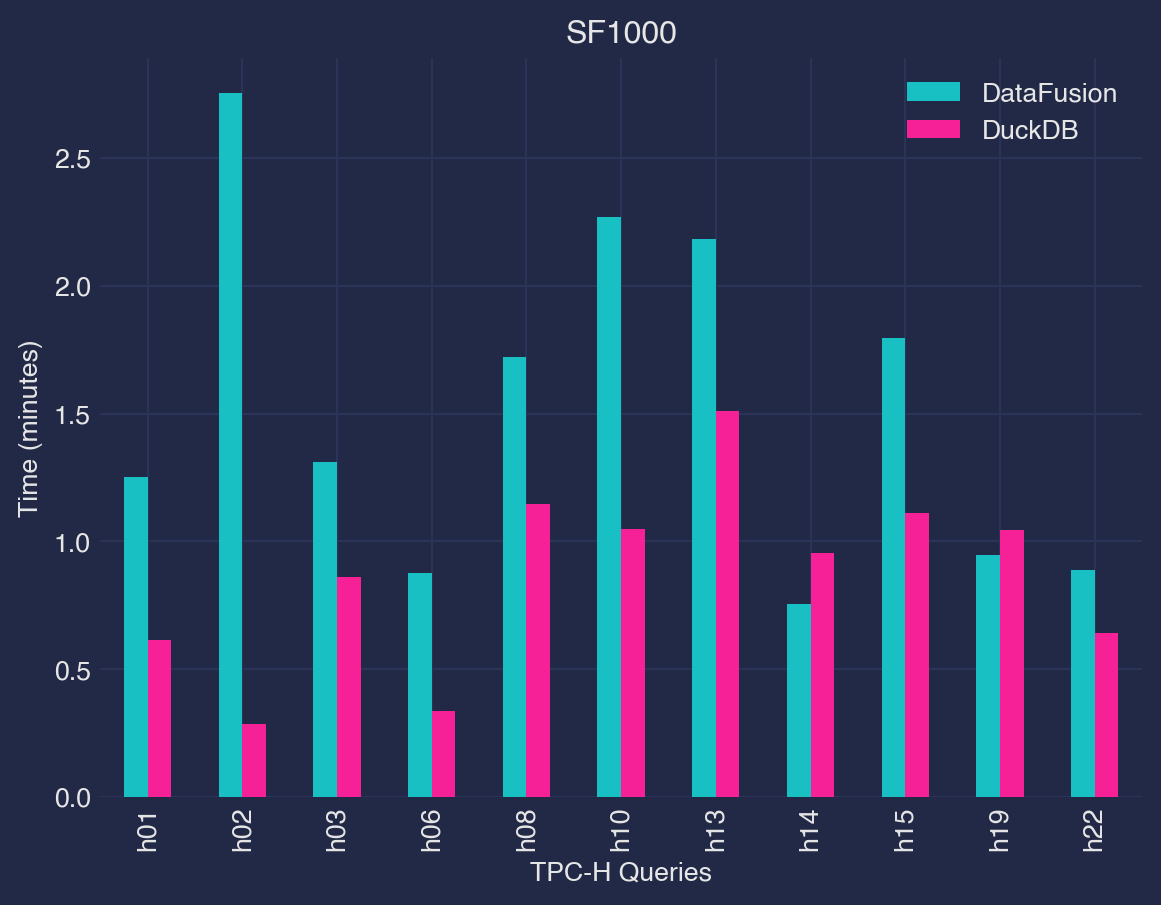
H14andH19show better execution times than DuckDB’s execution times. For all successful queries, on average the difference is less than 2x. - At the 100 GB scale factor, 4 out of 22 queries failed4.
H17andH18were killed and didnt fail gracefully. - At 500GB scale-factor, additional three queries
H07,H12,H20also failed due to out-of-memory errors.H21was killed and didnt fail gracefully. - At the 1 TB scale factor, 4 out of 21 queries failed due to running out of memory, while another 4 queries (
H17,H18,H19,H21) were killed. - The low CPU usage5 observed during TPC-H query execution implies that DataFusion may not be fully utilizing available resources for processing, which can impact its overall performance.
While the TPC-H results show areas for improvement in DataFusion, it’s important to recognize that the benchmark may not be the best fit for evaluating its capabilities. The true value of DataFusion lies in its extensibility and ability to extend, improve performance, and integrate with the wider ecosystem, making it an attractive choice for various data systems, including time-series, streaming etc. use cases.
TPC-H (Single Parquet)
I take an average of 4 runs for the execution time. Here are the details of the benchmark set-up:
| GitHub | https://github.com/hussainsultan/tpch-duckdb-bench |
| Database Version | datafusion 23.0.0 |
| Dataset | TPC-H 2.18.0_rc2 in Parquet format |
| Hardware | AMD Threadripper 3960X 3.8 GHz 24 Core, 128 GB Memory, 2TB NVME complete spec |
| Number of runs | 4 |
Expand to see the code to process the results
import pandas as pd
import scipy
import matplotlib.pyplot as plt
from IPython.display import Markdown, HTML
from tabulate import tabulate
plt.style.use("../pitaasmoothie-dark.mplstyle")
t1 = (
pd.read_csv(
"https://raw.githubusercontent.com/hussainsultan/tpch-duckdb-bench/main/results/consolidated.csv"
)
.assign(
freq=lambda x: x.apply(
lambda x: 4.3 if x.comment == "boost" else float(x.comment.split("Ghz")[0]),
axis=1,
)
)
.rename(columns={"name": "tpc_query", "datadir": "sf"})
.loc[lambda x: (x.success == True)]
.drop(["run_date", "success", "runno", "comment", "total_time_cpu", "db"], axis=1)
.groupby(["tpc_query", "threads", "freq", "sf"])[["total_time_process", "cpu_mJ"]]
.mean()
.reset_index()
)
t1 = t1[
t1.tpc_query.isin(
[
"h01",
"h02",
"h03",
"h06",
"h08",
"h09",
"h10",
"h13",
"h14",
"h15",
"h19",
"h22",
]
)
]
sf100 = pd.read_csv(
"https://raw.githubusercontent.com/hussainsultan/tpch-duckdb-bench/datafusion/results/datafusion/sf100_native.csv"
)
sf500 = pd.read_csv(
"https://raw.githubusercontent.com/hussainsultan/tpch-duckdb-bench/datafusion/results/datafusion/sf500_native.csv"
)
sf1000 = pd.read_csv(
"https://raw.githubusercontent.com/hussainsultan/tpch-duckdb-bench/datafusion/results/datafusion/sf1000_native.csv"
)
sf1000 = (
sf1000[sf1000.success == True]
.groupby(["name"])
.total_time_process.mean()
.reset_index()
)
sf500 = (
sf500[sf500.success == True]
.groupby(["name"])
.total_time_process.mean()
.reset_index()
)
sf100 = (
sf100[sf100.success == True]
.groupby(["name"])
.total_time_process.mean()
.reset_index()
)
d1000 = scipy.stats.gmean(sf1000.total_time_process) / 60
d500 = scipy.stats.gmean(sf500.total_time_process) / 60
d100 = scipy.stats.gmean(sf100.total_time_process) / 60
d1 = pd.DataFrame([d100, d500, d1000], index=["sf100", "sf500", "sf1000"])
d1.columns = ["DataFusion"]
d_1000 = sf1000.groupby(["name"]).total_time_process.mean() / 60
d_1000.rename("SF 1000")
sf100_duckdb = (
t1[(t1.freq == 4.3) & (t1.sf == "sf100") & (t1.threads == 48)]
.groupby(["tpc_query"])["total_time_process"]
.mean()
.reset_index()
)
sf500_duckdb = (
t1[(t1.freq == 4.3) & (t1.sf == "sf500") & (t1.threads == 48)]
.groupby(["tpc_query"])["total_time_process"]
.mean()
.reset_index()
)
sf1000_duckdb = (
t1[(t1.freq == 4.3) & (t1.sf == "sf1000") & (t1.threads == 48)]
.groupby(["tpc_query"])["total_time_process"]
.mean()
.reset_index()
)
sf100_duckdb = scipy.stats.gmean(sf100_duckdb.total_time_process) / 60
sf500_duckdb = scipy.stats.gmean(sf500_duckdb.total_time_process) / 60
sf1000_duckdb = scipy.stats.gmean(sf1000_duckdb.total_time_process) / 60
all_sfs = pd.DataFrame(
[sf100_duckdb, sf500_duckdb, sf1000_duckdb], index=["sf100", "sf500", "sf1000"]
)
duckdb = d1.join(all_sfs)
duckdb.columns = ["DataFusion", "DuckDB"]
duckdb.plot(kind="bar")
plt.xlabel("Scale-factor")
plt.ylabel(" Geomean Time (minutes)")
plt.show()
d_1000_duckdb = (
t1[(t1.freq == 4.3) & (t1.threads == 48) & (t1.sf == "sf1000")]
.groupby("tpc_query")
.total_time_process.mean()
/ 60
)
d_1000_duckdb.rename("DuckDB")
d_1000 = pd.concat([d_1000, d_1000_duckdb], axis=1)
d_1000.columns = ["DataFusion", "DuckDB"]
d_1000 = d_1000.dropna()
d_1000.plot(kind="bar")
plt.xlabel("TPC-H Queries")
plt.ylabel("Time (minutes)")
plt.title(
"SF1000",
fontdict={
"fontsize": "large",
"fontweight": plt.rcParams["axes.titleweight"],
"verticalalignment": "baseline",
},
)
plt.show()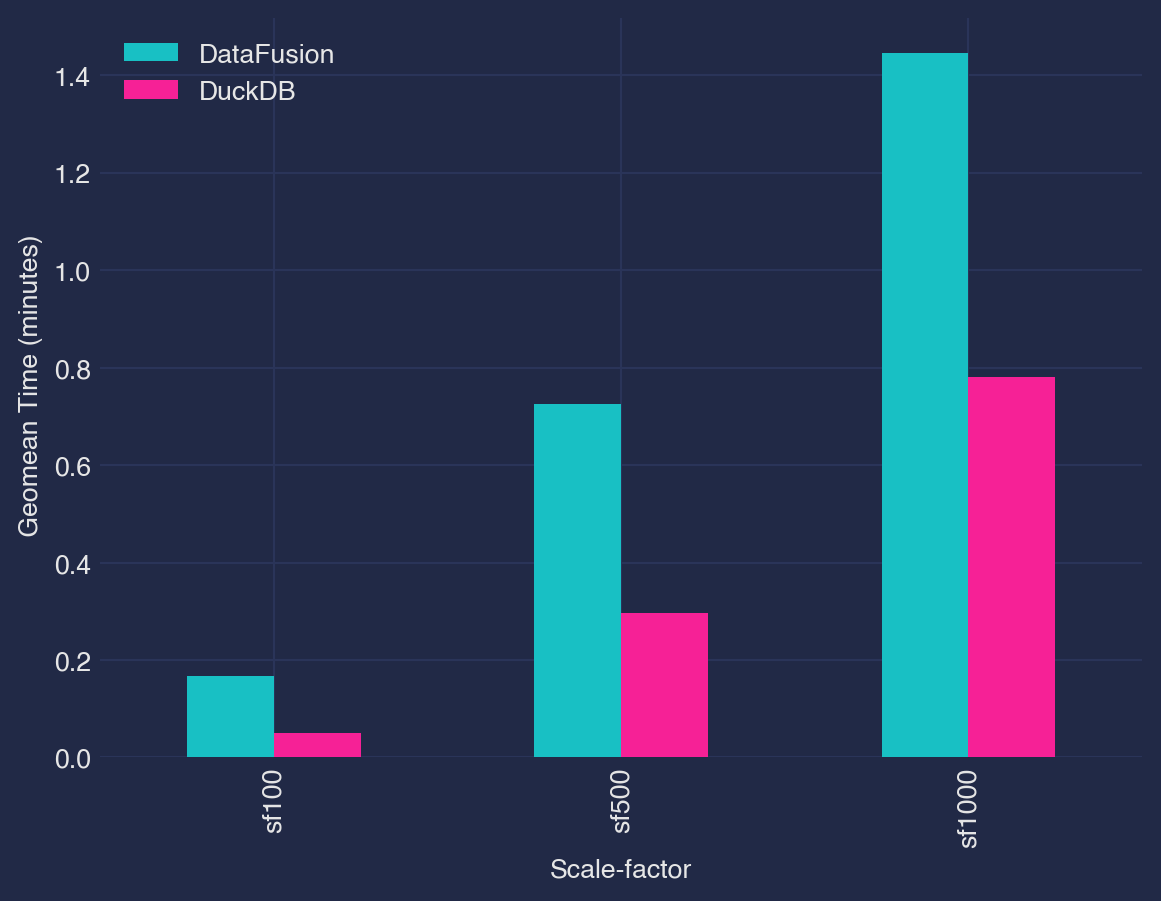
Failed Queries by Scale-factor
Code Example
Let’s try a simple Top-K query on orders table at scale-factor 10. Here is the SQL query that takes a table, sorts it by a value and shows the top 10 results.
import datafusion
import timeit
from datafusion import RuntimeConfig, SessionConfig, SessionContext
print(datafusion.__version__)23.0.0DataFusion exposes many configuration and runtime settings.
runtime = RuntimeConfig().with_disk_manager_os().with_fair_spill_pool(100000000)
config = (
SessionConfig()
.with_create_default_catalog_and_schema(True)
.with_target_partitions(8)
.with_information_schema(True)
.with_repartition_joins(True)
.with_repartition_aggregations(True)
.with_repartition_windows(True)
.with_parquet_pruning(True)
.set("datafusion.execution.parquet.pushdown_filters", "true")
)
ctx = SessionContext(config, runtime)
ctx.register_parquet("orders", "../../../fanniemae-benchmark/sf10/raw/orders.parquet")sql = """
SELECT
t1.o_orderkey AS o_orderkey,
t1.o_totalprice AS o_totalprice
FROM orders AS t1
ORDER BY
o_totalprice DESC
LIMIT 10;
"""
start_time_process = timeit.default_timer()
ctx.sql(sql).collect()
total_time_process_datafusion = timeit.default_timer() - start_time_process
Markdown(
tabulate(
pd.DataFrame({"datafusion": total_time_process_datafusion}, index=["Time (s)"]),
headers=["DataFusion"],
)
)| DataFusion | |
|---|---|
| Time (s) | 0.396819 |
Conclusion
In conclusion, there are many benefits that are driven by unbundling of the database architecture. It can lead to lower costs, more flexibility, and a better user experience. DataFusion is perhaps the most mature unbundled OLAP that is being adopted by database developers. However, there are also some challenges to consider, such as the need for further enhancements in DataFusion’s execution engine. For example, supporting a wider set of operators to support TPC-H queries, additional out-of-core support, and improving core engine performance as it relates to comparisons with state-of-the-art systems.
Unbundled OLAP architectures offer a number of benefits for analysts, data scientists, and developers. By decoupling the various components of a database, these architectures allow for better utilization of cloud resources, the ability to select the necessary database parts based on specific use cases, and easier integration of SQL pipelines into code and systems.
Acknowledgment
I’d like to thank Andy Grove for providing his review of the benchmarking set-up and receommending improvements. Thanks to @min_djo for his gracious review and feedback.
Footnotes
The first mention of this type of unbundling that I could find is from this talk by Julien Le Dem in 2018. Here is a article on Deconstructed Database.↩︎
InfluxDB is perhaps the largest commercial adopter, along with community projects like Ballista↩︎
If I used the default
datafusionconfigurations for the Python package, the TPC-H benchmark is about ~7x slower and also had more Out-of-memory issues vs the configurations used below:
↩︎runtime = ( RuntimeConfig().with_disk_manager_os().with_greedy_memory_pool(64000000000) ) config = ( SessionConfig() .with_create_default_catalog_and_schema(True) .with_target_partitions(8) .with_information_schema(True) .with_repartition_joins(True) .with_repartition_aggregations(True) .with_repartition_windows(True) .with_parquet_pruning(True) .set("datafusion.execution.parquet.pushdown_filters", "true") )H16 gave me a “Schema at index 0 was different” error↩︎
My benchmarking utility used to have a CPU util metric that I do not trust. However, just watching
topoutput while the benchmarks are running still didnt show me the same type of CPU “burn” that I see from DuckDB, as an example. I know totally anecdotal.↩︎